Editing individual MARC records based on spreadsheet data
A process I developed for Georgetown Law Library’s Digital Initiatives department, December 2016.
Background
The Digital Initiatives department faced a quandary.
We had been working on digitizing library materials, and wanted to insert links to our items in the library’s online catalog. This seemed like a relatively straightforward endeavor. On the Digital Initiatives (DI) side, we had the data to easily produce a spreadsheet of URLs and bibliographic records that matched. All we wanted to do was take this information and make the links visible in our catalog’s record display.
Essentially, we wanted to do this (use MARC 856 fields to generate active links):
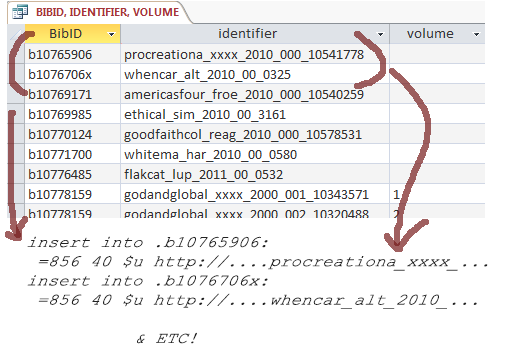
The stumbling block
Trouble was, our library was using Sierra, the integrated library system from Innovative Interfaces, Inc., and Sierra did not have the capacity to use such a spreadsheet. (Or more accurately, our version and instance of Sierra did not.) From my time working in cataloging, I was pretty familiar with Sierra and its functionality. We did have methods at hand to perform “coverage loads”, i.e., linking bib records to electronic resources like e-serials via spreadsheet data. But after some testing, we found that coverage load, designed to include data like journal coverage, was not a good solution for digital monographs. We also had API access to our Sierra data, which was essential to our tasks in DI, but lacked write access to our records, so we couldn’t just update our MARC records with external programming tools. We could also bulk-import and bulk-export batches of MARC data (which turned out to be part of the solution).
I spent a while going through the more obscure features of MARCEdit, the cataloger’s default tool for manipulating MARC records. MARCEdit was certainly capable of rapidly analyzing MARC records en masse, and performing rich edits via RegEx and other sophisticated methods. But try as I might, I couldn’t find any way to do what I needed in MARCEdit either. I needed to use an external source (the DI spreadsheet) and pull that info into individual bib records. MARCEdit just didn’t have the a method to do this type of mapping from an external document.
The good folks at Innovative certainly could have done this on our behalf, editing our records for us based on whatever criteria we needed. We went so far as to get a price quote, and it was not absurd. But I was convinced that there had to be a way to make it work locally.
The solution
The crucial realization was, if I could just read through a bunch of MARC data line by line, I could watch out for certain pieces of information (like the bibliographic ID number) and then insert an 856 link into an individual record by comparing that ID number to the external spreadsheet. This sounds complicated, but it isn’t really. The only tricky part is converting MARC (a binary format, natively) into text, and vice-versa. Luckily, MARCEdit has a command-line version called cmarcedit that can easily accomplish this.
I had been learning Python for months by December of 2016, when this logjam was becoming mission-critical. I’d even dipped a toe into MARC manipulation via the pymarc library. Ultimately, though, my solution to our problem didn’t especially require Python; I used it as a convenience, but any programming language (like Perl) would be just as good.
My solution in Python looks like this:
- Take a MARC file as output from Sierra: a single binary file that contains multiple bibliographic records.
- Send the file to cmarcedit to “break” the MARC file into a plain-text .mrk file.
- Go through the resulting file line-by-line, dealing with Sierra-induced problems as they come, identifying the bib id number of each record, and inserting an 856 line
- Save the resulting file as a temporary text document, and then sending that file back to cmarcedit which compiles it into a binary MARC file again.
After creating the new MARC file, I was able to upload it into Sierra and successfully overlay existing records in our system, with the new links included. Hurrah! We totally celebrated this one in the office!
Outcomes
For my department, this method is really just a stopgap measure. I ran into some difficulties, not so much because of my technique, but because of inconsistencies in the legacy MARC data I had to work with. Certain ill-formed records (often dating back to the data’s origins in the ’80s) threw errors on load, and I had to make corrections on a case-by-case basis. While sustainable at the numbers I was working with (say, a thousand records at once), I don’t think this method would be effective enough on a mass scale of tens or hundreds of thousands.
My technique is also a stopgap because my library is going to move away from Sierra to Ex Libris’s Alma in the next year. Alma has a lot more of this type of manipulation baked in to its architecture, so we will re-assess this project and have to develop new (and hopefully better) techniques in the near future.
The code
I placed the whole code segment over on GitHub, where maybe it will be useful for somebody else someday.
The cool thing about this little program, for me, was that it was the first time I successfully integrated an external command-line tool like MARCEdit within Python, and so I learned about programmer-popular phrases like stdout and stdin. Now I’m all down with the stackoverflow lingo. It was gratifying to watch the cmarcedit outputs pop up in my Python program.
When the script is run, the output is like this:
processed b12464715 - added 1 link processed b12467133 - added 1 link processed b12467236 - added 1 link processed b12470788 - added 1 link processed b12509590 - added 1 link Compiling MARC record... Beginning Process... 1369 records have been processed in 0.307031 seconds. deleted 4511 lines of extraneous 9xx fields -- check log for details Added 1164 links; modified 1087 bib records.
And here is an example of a single finished MARC record after going through this modification. Note that you probably have to scroll to the right to actually see the resulting link!
=LDR 01810cam 2200481 a 4500
=001 ocn785865152
=008 120702s2013\\\\ctuaf\\\\\\\\\000\0deng\\
=020 \\$a9780300151930 (cl : alk. paper)
=020 \\$a0300151934 (cl : alk. paper)
=040 \\$aDLC$beng$cDLC$dBTCTA$dERASA$dUKMGB$dBDX$dOCLCO$dYDXCP$dYNK$dQGK$dYUS$dBWX$dGUL$dMARCIVE
=043 \\$ae-gx---
=050 00$aB3181$b.S54 2013
=100 1\$aSherratt, Yvonne,$d1966-
=245 10$aHitler's philosophers /$cYvonne Sherratt.
=260 \\$aNew Haven :$bYale University Press,$cc2013.
=300 \\$axx, 302 p., [8] p. of plates :$bill. ;$c24 cm.
=599 \\$ayywPML.
=600 10$aHitler, Adolf,$d1889-1945.
=650 \0$aPhilosophers$zGermany$xHistory$y20th century.
=650 \0$aPhilosophy, German$y20th century.
=856 40$xInternet Archive$zDigitized copy available for e-checkout$uhttp://archive.org/details/hitlersphilo_sher_2013_000_10854510
=970 01$tList of Illustrations$pix
=970 01$tAcknowledgements$pxi
=970 01$tDramatis Personae$pxii
=970 01$tPrologue$pxv
=970 01$tIntroduction$pxvii
=970 11$tPart I
=970 11$l1.$tHitler: The {grave}bartender of genius'$p3
=970 11$l2.$tPoisoned Chalice$p35
=970 11$l3.$tCollaborators$p62
=970 11$l4.$tHitler's Lawmaker: Carl Schmitt$p92
=970 11$l5.$tHitler's Superman: Martin Heidegger$p104
=970 11$lpt. II $tHitler's Opponents
=970 11$l6.$tTragedy: Walter Benjamin$p129
=970 11$l7.$tExile: Theodor Adorno$p160
=970 11$l8.$tJewess: Hannah Arendt$p189
=970 11$l9.$tMartyr: Kurt Huber$p207
=970 11$l10.$tNuremberg Trials and Beyond$p229
=970 01$tEpilogue$p264
=970 01$tNotes$p266
=970 01$tBibliography$p286
=970 01$tIndex$p295
=949 \\$a*recs=b;ov=.b12071882;ct=04-01-13;