Modeling state changes for a digitization database
Originally developed for course INST733, Database Design, at the University of Maryland, Fall 2016
Background
I took a course in database design in part because it was relevant to my work. My department, Digital Initiatives, was opening up a discussion with the library’s Electronic Resource Services department to develop a new digitization workflow tool that could replace an existing unwieldy Access database. I wanted to take advantage of the class and spend some time thinking about possible models for managing and recording digitization processes.
Acknowledgments
As a class project, this was a team effort. I worked with classmate Sachin Grover to flesh out the overall database design. I also drew on the work of my colleague at Georgetown Law Library, Matt Zimmerman, who was already reconceptualizing our digitization database. However, the ideas presented here are substantially my own, as I think both Sachin and Matt would attest.
Database schema
For the purposes of the course, Sachin and I had to develop a relational database using SQL queries. We analyzed the structure of our data and normalized the hell out of it. You can see it in this Entity Relationship Diagram:
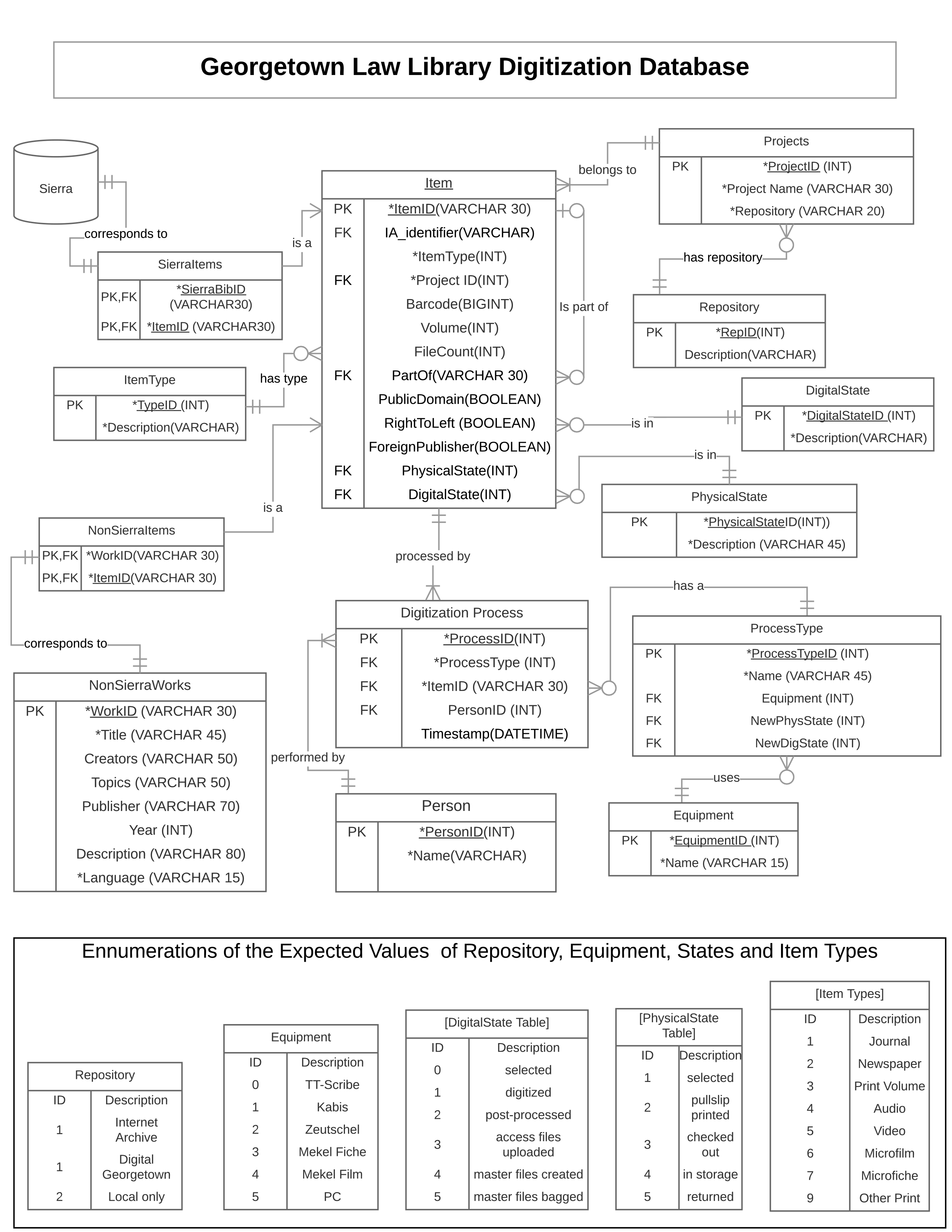
However, the key innovation in our model lies in just a few of the attributes and relationships. I was looking for a method of modeling workflow and changing states of our digitized items. Sachin pointed me in the direction of this extensive treatment of designing a workflow database that eventually put me on an interesting path.
What I ultimately realized, after sketching out relationship patterns repeatedly on pen and paper, was that it was possible to give items in the database state attributes. For digitization, I was interested in tracking items’ physical state — such as the location of books — and digital state — like the generation of access files or archival files, or presence in an external repository. By numbering these states, I could establish a workflow that presumes that items pass from one state to another in a certain order.
In order to make these states useful, we could track digitization processes, by which I mean actual things that happen to an item: a book is pulled from a shelf, or scanned, or images are processed in a certain way, or files are uploaded to a certain place. Each of these processes could be recorded in the database with a timestamp (and potentially a human operator id attached), and each process could alter the physical and/or digital state of the material. I found this to be elegant and extremely practical.
The pertinent part of the ERD looked like this:
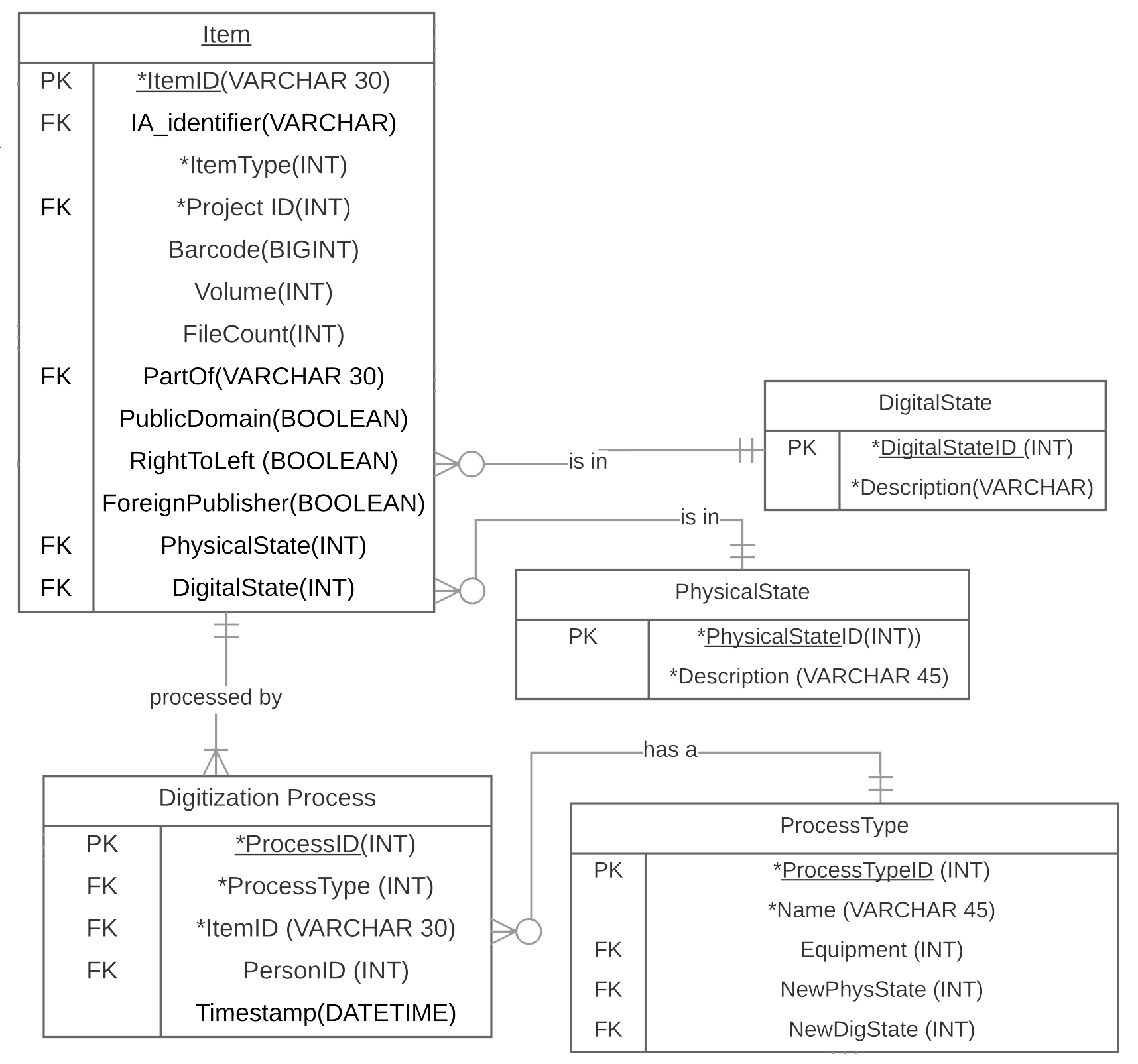
Basically, we can add a row to the digitization process table (representing something done at a particular time by a particular person), and update an item’s various states. In the table below, I’ve added some processes to a couple of sample items, and those process types trigger particular changes to the physical and digital states.

Here is a live demonstration of the model, which might make more sense than just staring at data tables:
The aftermath
At my library, I presented this data model to the librarians who are actually building a replacement for our Access database, and elements of my work are definitely part of a new emerging digitization workflow tool. I think this was a definite marker of success.
However, we still are not really utilizing my key insight — that we can model and track various different types of states, and that particular workflow steps can modify multiple types of states. I hope to revisit this idea in a future project. The general concept could easily be extended to include additional item states such as metadata management and digital preservation, or be used for a variety of complex workflow situations.
Appendix: The trigger in SQL
For the purposes of the class, we worked in MySQL Workbench, and I did not find it especially simple to design the trigger to make this idea actually work. So I am recording it here for posterity — here is some sample SQL to compile information from different data tables and update items to their corresponding values: