Technology Exploration: XML, EAD, XSLT, and finding aids
The following was a final project for a course in Creating Information Infrastructures in Spring of 2016 at the University of Maryland. I used real-world data from the Special Collections at my library in an attempt to lightly edit the styles of our finding aids. This was my first real exposure to XSL and XSLT and I am not eager to wade back into those waters. However, at least I would know what I’d be getting into. This was originally posted on UMD-provided webspace.
Jeff Gerhard · May 2, 2016 · LBSC671
I began this capstone project [for the LBSC671 class] with a few basic goals:
- To learn about XSL and XSLT transformations. I was familiar with XML, but not XSL or other tools for transforming it.
- To learn the gist of EAD, the Encoded Archival Description format.
- To practice using Archivists’ Toolkit — At my library, I currently work in the Digital Initiatives department within a broader Digital Initiatives and Special Collections division, and I am open to collaborating with the Special Collections side of the division and learning to use their tools.
- To use my discoveries and attempt to improve upon my library’s manuscript finding aids, which are not much modified from the default output from Archivists’ Toolkit.
I found this project humbling.
1. XSLT
On the first point, the basics of XSLT are not too difficult. I spent some time earlier in the semester going through XML training courses on lynda.com (see certificate of completion) where I was pretty easily able to follow along and use .xsl files to adjust the order of XML elements, provide them with display styles, etc. I’ve included examples of some of these training documents in a subfolder; the XML file from the training session is sorted by an “availability” attribute. I began using the Oxygen XML Editor that I have installed on my work computer, along with Notepad++, the popular text editor, and learned a lot about both of these tools.
{kind=link}
Similar to the lynda.com examples, I was easily able to follow the w3schools tutorial on XSLT, transforming a CD catalog XML file into an HTML table. Our course textbook includes some more sophisticated examples of XSLT for basic transformations of MARCXML records, showing how XSLT is really a programming language and not a style formatter like CSS.
I learned enough about XSL to feel that I had a sense of what it does, but not enough to feel especially confident about my project. Still, my programming explorations outside of XSLT were going really well, and I felt that I would be able to achieve all my goals. I was unprepared, though, for the difficulties of transforming EAD documents.
2. EAD
EAD is an understandable standard, but certainly not a simple one. It includes hundreds of tags, many of them with non-obvious names like the repeated <c> tags. Trying to get a good feel for EAD felt to me like trying to learn all of HTML from scratch rather gradually building up knowledge from basic elements to advanced ones.
I found a number of useful web resources, but none more helpful than the Library of Congress’s official site which includes a history of EAD development, a critical tag library, and some helpful links. I found myself getting the general idea of how EAD documents are organized, though I had some trouble understanding everything since I only have a passing knowledge of archival rules and standards. I was beginning to realize how difficult this project might become.
3. Archivists’ Toolkit
This spring, the Special Collections department began installing Archivists’ Toolkit (AT) on a number of new computers, and I asked if I could experiment with it at the same time. (We are all aware that AT is being superseded by newer software, but are not anticipating a shift to ArchiveSpace right now.) I was less interested in creating new metadata than in the export functionality. AT can export EAD XML files, and has a “report” function that exports HTML and PDF files. The application comes installed with some default XSLT stylesheets that create clean but fairly generic finding aids.
I didn’t have much trouble understanding AT, though modifying those default XSLT stylesheets was not always straightforward. The .xsl files (at least on Windows) reside in a protected directory that requires administrator privileges to edit. This was troubling as I had to always use a text editor in administrative mode to edit the sheets, and I had trouble opening up other documents in a text editor at the same time. This Windows quirk is not an AT problem, though.
I had a few problems in AT worth mentioning, though. The software does not have a method of previewing transformations or otherwise working with XSL. It seems like the XSL functionality is almost tacked on and not an intrinsic part of the application. It would have been extremely helpful if there were native tools dealing with XPATHs or helping with XSL language. Instead, I had to make edits to the .xsl files, then export HTML or PDF documents, then see what my edits had done. (Often enough, they broke the entire exported file.)
Another problem with Archivists’ Toolkit is its inflexibility. My library’s Special Collections librarian mentioned to me in passing that it would be nice to include images in our finding aids. The EAD specifications seem to allow for this possibility via <ptr> pointer tags, but I spent a long time puzzling over where this could be included in AT and was unable to get this idea ever to work.
4. Finding Aids
Our Special Collections librarian had some additional concrete ideas for updating the Georgetown Law Library finding aids. I was pleased to find that most of her wishes seemed to be closer to CSS issues (which I felt confident enough to handle) than to purely XSL problems, which might be more difficult. She and I used an example finding aid published in the Digital Georgetown repository. It is hosted here and I will be focusing mainly on the HTML version. I’ll be referring to this as the “current version” of the finding aid, and it may be helpful to keep open in a tab. The original EAD XML for this file is also here in text form.
One relatively simple issue we wanted to change was the box drawn around the “Preferred Citation” area of the current finding aid:

We also envisioned removing the same box in the PDF version of the finding aid:

The next goal was to do something about the left-side table of contents menu. We wanted to make the links have a “visited” color. We also looked at examples of other universities’ finding aids that had fixed menus, dropdown menus, and expanding menus. Without any firm commitment, we were open to some functionality like this in our finding aid.
I felt that all of this was eminently achievable.
Fixing the visited color
The default XSL file in AT is titled at_eadToHTML.xsl. I’m including a copy of the current version in use at my library as a text file here.
Since I knew a lot about CSS, I didn’t have much trouble identifying and changing the visited link info. I just switched out this version...
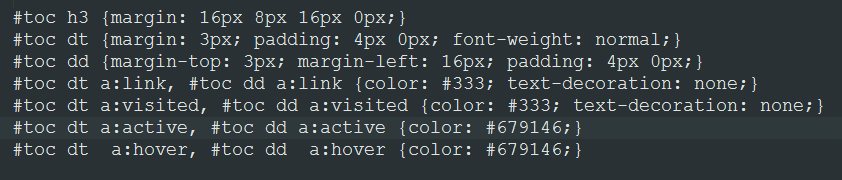
... for this one, changing the visited color:
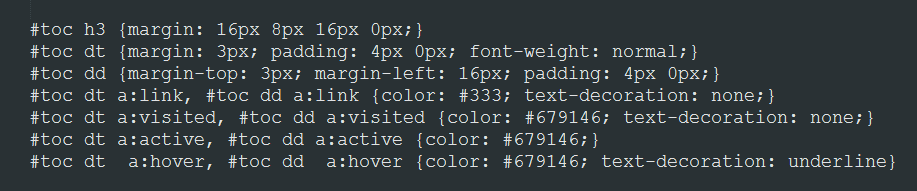
If only it were all that simple!
The box around the “Preferred Citation”
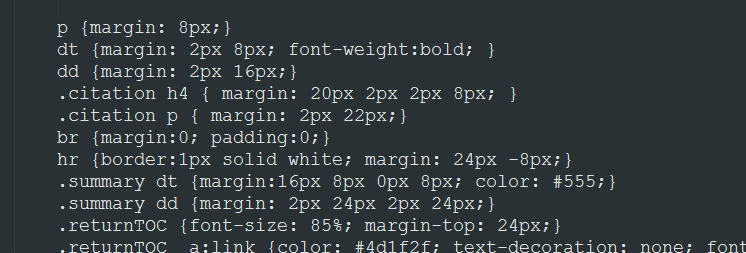
I thought that this would also be a simple CSS issue, but I started to run into snags as soon as I tried to trace the HTML source code back through the XSL sheet to the EAD XML. In the HTML, the items above the Preferred Citation are <dt> and <dd> tags, while the Preferred Citation is in its own <div> with an <h4> and <p> holding the information:
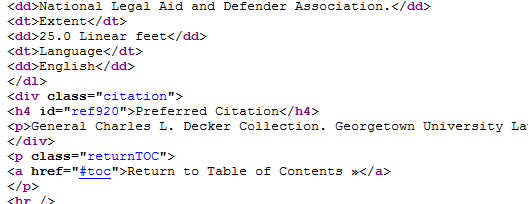
In the XML source, this information was separated from the other items in the finding aid list, and defined differently:
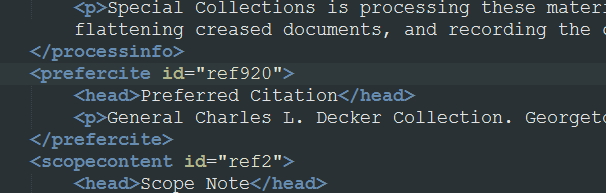
I found that I could adjust the XSL to get rid of the box quite easily by changing the css on the <div>, but had great difficulty recreating the <dt> and <dd> format of the preceding list. I needed to be able to pull out the child nodes of the <h4> and <p> and put them into the definition list. I spent a considerable amount of time on this until I abandoned the effort, and simply adjusted the css to make it look like the <h4> and <p> were part of the list. Hacking css is easier than XSLT, though I admit it defeats some of the purpose of having structured XML data in the first place.
The problem I started running into was that the XSL was just too complex to follow. This was not a matter of sorting four types of coffee by availability. This was almost 2000 lines of code, designed to handle all kinds of marginal cases. I would try to change something in the XSL and find that what I changed was just a backup transformation in case the actual one could not match our XML. The thing I would want to change would be in some other <xsl:template> section entirely. I found XSL non-intuitive and sometimes overwhelming in scope.
But here is the hacky way I got rid of the box:
For the PDF version, I was able to remove the box but could never replicate this css hack, so I would say my effort was a failure. I found that there was little to no documentation for XML-to-PDF transformation, and I have no familiarity with hand-coding PDF styles. Here is an example of a finding aid PDF where I could remove the drawn box but not format the results properly:

The Table of Contents menu
Most of my experience with web design is from quite a few years ago, but I have kept up with it enough to think I could probably convert the table of contents list into something more dynamic that would stay on the left-hand side as the user scrolled down. I played with a few scenarios, trying to come up with an overall web design idea that would look appropriate and work consistently without being too complex.
I found that there were a number of simple javascript options to keep an element like our Table of Contents menu from scrolling up off the screen — this is referred to as a “sticky” position. (An actual pure-css { position: sticky } property has some browser support, but is not universal enough to replace the javascript.)
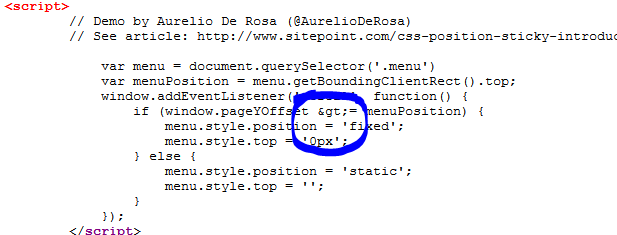
I used a script from this site and tested it a few times, and it seemed to work perfectly in tests when I simply added the script to an .html file. My menus on the left were scrolling up and then sticking to the top. But when I tried including the script in the XSL so that it would be in the exported HTML, I started pulling out my hair trying to get it to work. Pasting the code into html worked. If I pasted the identical code into the XSL, the <script> tags appeared to come through fine, but it just would not work. Finally, after comparing code line by line, I realized that a > sign was being converted in the transformation into >, like this:
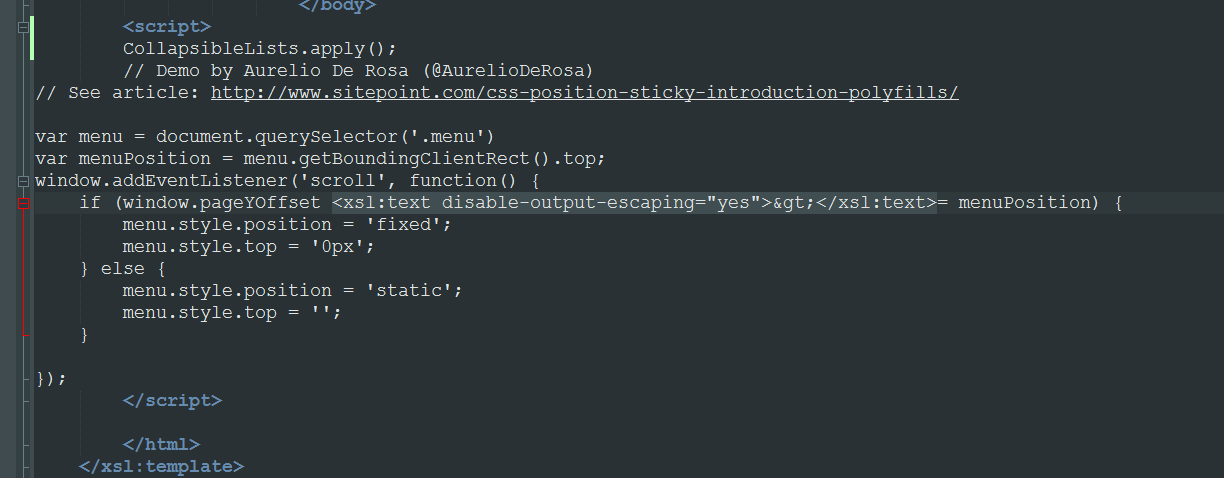
With some more research, I found that I could escape the greater-than sign with XSL code. The script finally worked. Here is how I had to code it in the XSL:
From here, I attempted to use some scripting tools like jquery to make the menu subfolders collapse and expand. I managed to implement a couple of working examples by editing the HTML output directly. Here is what they looked like:

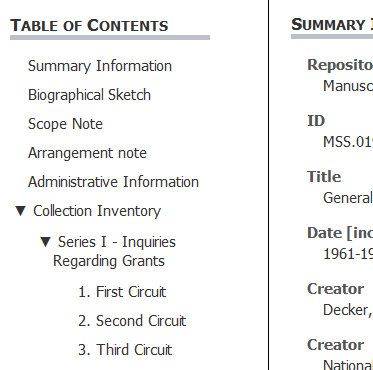
The attempt on the right side above worked well as a proof of concept — I put a working example here based on my own HTML and javascript editing. However, I could not replicate this model via XSL. The problem was that the default XSLT from AT pulled together a number of XML elements into the menu list, with complex statements governing their display based on the XML structure and various attributes. The relevant bit of XSL looks like this:
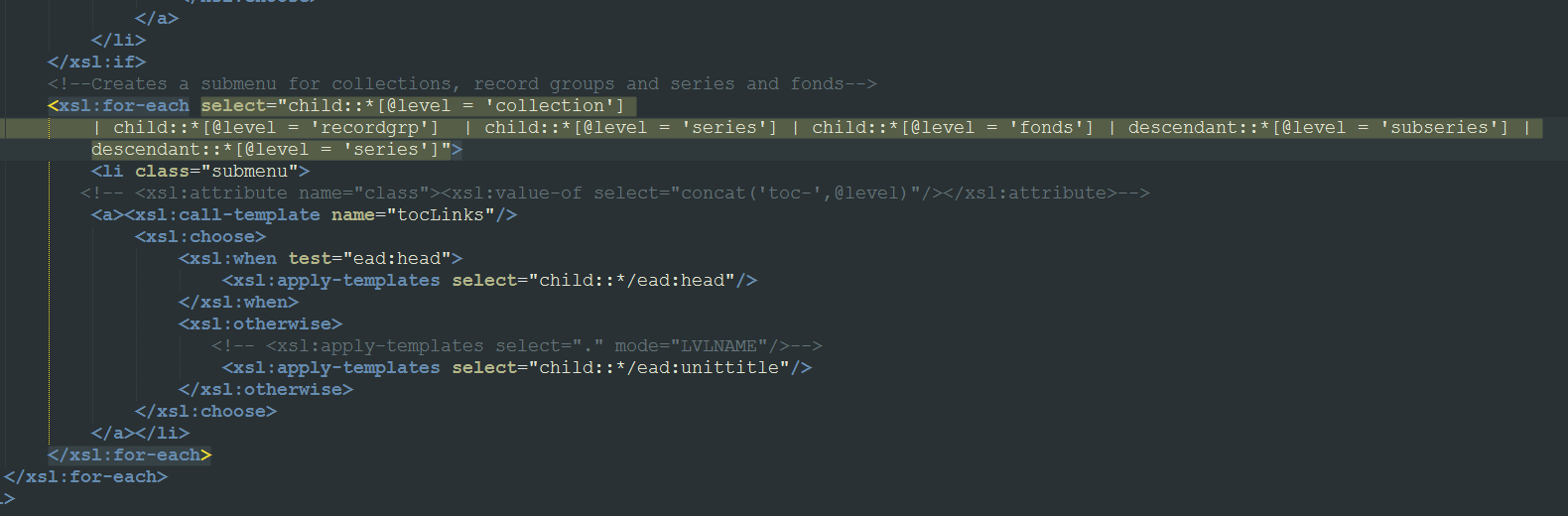
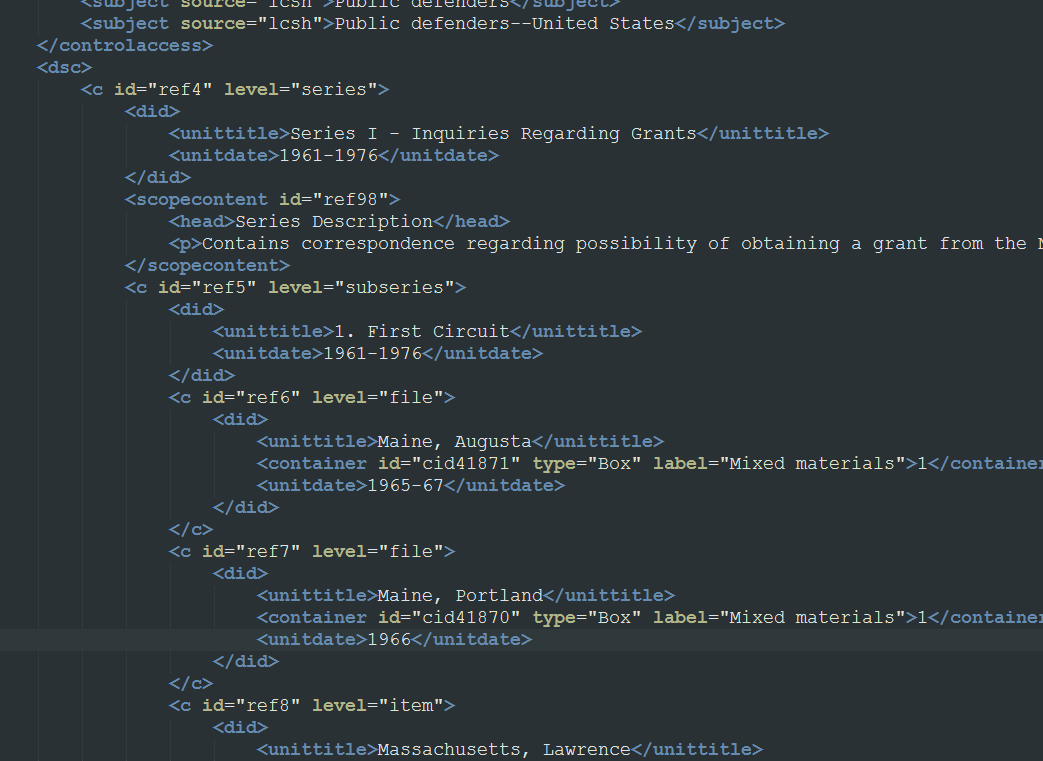
I needed to create nested <ul> lists in a particular format. I was able to swap around the default <dd>s for <li>s and make similar changes, but couldn’t fundamentally alter the structure enough to create nested submenus in the resulting HTML. I understood basically what was needed: a way to detect whether a series had a subseries, and a way to create a (HTML) submenu based on the series’ child nodes. But I could never get it to work. This was doubly frustrating because the original EADS XML has a decent structure to work from:
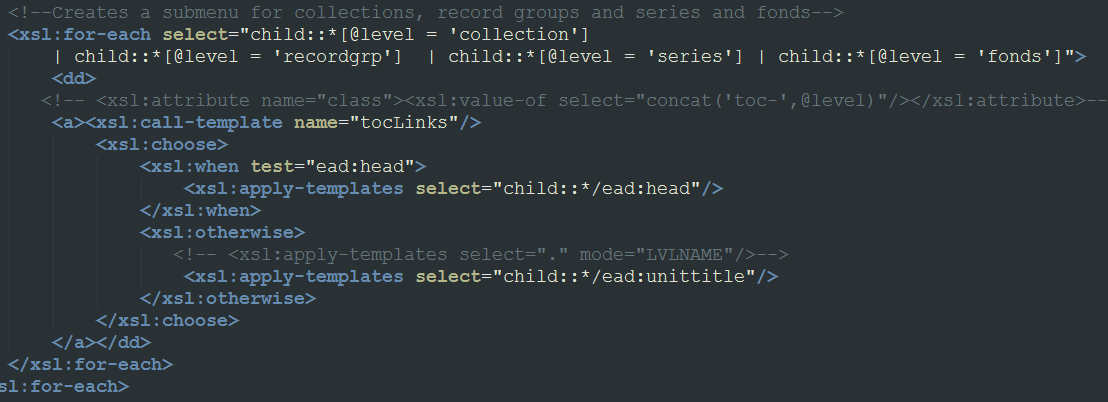
In the end I had to abandon my efforts to create a nesting menu and stick with the basic Table of Contents with my added “position:sticky” code. The only remaining problem was that many of our Tables of Contents — including the one for my main example file, the Decker collection — are very long and unlikely to fit on one screen. I decided to chop out the subseries information from the sidebar, since it would be less needed if users could jump more quickly through the entire document by keepin the Table of Contents on screen at all times. I modified the .xsl to delete the subseries from the Table of Contents list:
Pleased with the results in the end, I also changed the “Return to Table of Contents” links scattered throughout the finding aid into “Return to Top”, tweaked the CSS a tiny bit to my liking, and decided I had completed as much as I could of my original plan.
Final results and thoughts
The final version of my finding aid for the Decker collection is here. (Compare to the current version.) I also exported one additional finding aid from Archivists’ Toolkit and posted it here (compare to the current version). A text copy of my final XSL file is here.
I found working with XSL far more difficult than I anticipated. Even with hours of study, I could barely keep straight any of the XSL programming functions. It was markedly more difficult than programming languages I have touched upon in the past like javascript and python — which I chose for my programming exercise for this course and found comparatively easy to pick up. XSLT also suffers from a lack of resources due to its relative obscurity. For many programming languages, sites like stackoverview are full of tips and discussions. I found very little help available for XSLT.
Probably the most enjoyable part of this project was going through a blog post advocating for archivists to use XQuery rather than XSLT. The author’s recommended software tool, BaseX, was easy to install and includes a lot of great features for working with XML data, including visualizations and methods of converting all or parts of XML documents to and from other formats like HTML, json, and csv spreadsheets. I attempted to use this tool and learn some XQuery, but found it was also difficult and a distraction from my task at hand. However, I will come back to BaseX and experiment with it in the future. I find it easy to believe that XQuery would be easier to master than XSLT.
For our finding aids, my only thought would be that a mobile-friendly version could only be helpful — though my version did display pretty well on my phone, especially in landscape mode. I think it is also worth thinking about ways to make our data more open to the Internet, and static HTML and PDF files are not the best way to do that when the data is so well-structured in XML form. In the future I will be interested in seeing what tools arise to make use of archives data, and allow archivists to make their well-constructed data more integrated into the web.